ETL Pipelines in Python Explained with Code and Examples
Data Analytics Data EngineetingPosted by admin on 2025-09-20 21:27:34 |
Share: Facebook | Twitter | Whatsapp | Linkedin Visits: 281
ETL Pipelines in Python Explained with Code and Examples
In the era of data-driven decision-making, extracting valuable insights from data is vital for organizations. One of the key processes in data management is the ETL (Extract, Transform, Load) pipeline. In this long-form article, we'll explore ETL pipelines in Python in depth, providing clear explanations, code examples, and a comprehensive understanding of how to implement ETL workflows efficiently.
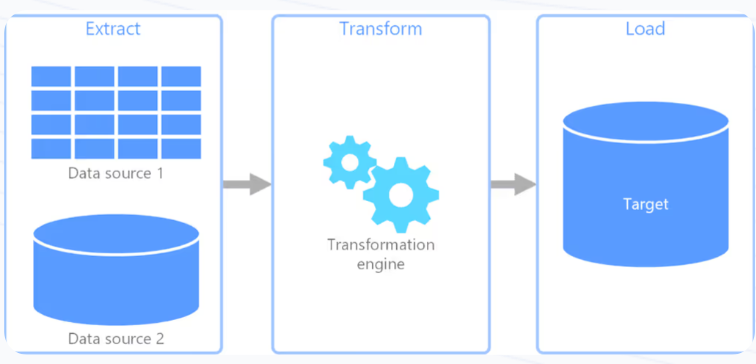
What is ETL?
ETL stands for Extract, Transform, and Load, representing the three crucial steps involved in processing data from various sources to a target data warehouse or database.
Extract: This stage involves gathering data from different sources, which could be databases, APIs, flat files, or web scraping.
Transform: In the transformation phase, the extracted data undergoes various processes to clean, normalize, or enrich it. This could involve filtering out duplicates, changing data formats, or applying business rules.
Load: The final step is loading the transformed data into a target destination, such as a data warehouse or a database where it can be accessed for analysis.
An ETL pipeline can be executed on a scheduled basis or triggered by specific events, and it plays a crucial role in ensuring that decision-makers have access to relevant, accurate, and timely data.
Why Use Python for ETL?
Python is an excellent choice for building ETL pipelines for several reasons:
- Ease of Use: Python's syntax is clear and straightforward, making it easy to write and maintain code.
- Rich Ecosystem: Python has a vast array of libraries and frameworks, including Pandas, NumPy, and SQLAlchemy, which simplify data extraction, transformation, and loading operations.
- Integration: Python easily integrates with various data sources (APIs, databases) and can handle a wide range of data formats (JSON, CSV, XML, etc.).
- Community Support: With a large and active community, finding support or resources for Python is relatively easy.
Components of an ETL Pipeline
Let's break down the components of an ETL pipeline:
1. Data Sources
These can be anything from a database to an online API. We'll demonstrate extraction from a sample SQLite database and a public API.
2. Data Extraction
For our example, we'll extract data from a SQLite database and a public API that provides JSON data.
3. Data Transformation
We'll clean and format the data, ensuring it's in the right structure for loading into our destination.
4. Data Loading
We'll load the transformed data back into our SQLite database and show how to do this with SQLAlchemy.
ETL Pipeline Example
Let's create a simple ETL pipeline that extracts employee data from a SQLite database, transforms it, and then loads it back into another table in the database.
Step 1: Setting Up the Environment
First, make sure to install the required libraries:
pip install pandas sqlalchemy sqlite3 requests
Step 2: Sample Data
For demonstration, we will create a SQLite database called employees.db with two tables: raw_employees and transformed_employees.
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('employees.db')
# Create cursor
cur = conn.cursor()
# Create tables
cur.execute('''
CREATE TABLE IF NOT EXISTS raw_employees (
id INTEGER PRIMARY KEY,
first_name TEXT,
last_name TEXT,
salary REAL
)''')
cur.execute('''
CREATE TABLE IF NOT EXISTS transformed_employees (
id INTEGER PRIMARY KEY,
full_name TEXT,
annual_salary REAL
)''')
# Insert sample data
cur.execute("INSERT INTO raw_employees (first_name, last_name, salary) VALUES ('John', 'Doe', 50000)")
cur.execute("INSERT INTO raw_employees (first_name, last_name, salary) VALUES ('Jane', 'Smith', 60000)")
# Commit changes and close connection
conn.commit()
conn.close()
Step 3: Extract Data
Now that we have our database set up, it�s time to extract data from the raw_employees table.
import pandas as pd
import sqlite3
def extract():
conn = sqlite3.connect('employees.db')
df = pd.read_sql_query("SELECT * FROM raw_employees", conn)
conn.close()
return df
# Extracting data
raw_data = extract()
print("Extracted Data:")
print(raw_data)
Step 4: Transform Data
In the transformation stage, we will combine the first and last names and convert the salary to annual.
def transform(df):
# Combining first and last names
df['full_name'] = df['first_name'] + ' ' + df['last_name']
# Renaming the salary to annual_salary
df = df.rename(columns={'salary': 'annual_salary'})
# Select only the columns we need
df = df[['id', 'full_name', 'annual_salary']]
return df
# Transforming data
transformed_data = transform(raw_data)
print("\nTransformed Data:")
print(transformed_data)
Step 5: Load Data
Finally, we will load the transformed data into the transformed_employees table.
def load(df):
conn = sqlite3.connect('employees.db')
df.to_sql('transformed_employees', conn, if_exists='replace', index=False)
conn.close()
# Loading the data into the database
load(transformed_data)
print("\nData Loaded Successfully.")
Complete Pipeline Function
Combining all the steps into a complete ETL process:
def etl_pipeline():
# Extract
raw_data = extract()
print("Extracted Data:")
print(raw_data)
# Transform
transformed_data = transform(raw_data)
print("\nTransformed Data:")
print(transformed_data)
# Load
load(transformed_data)
print("\nData Loaded Successfully.")
# Running the complete ETL pipeline
etl_pipeline()
Conclusion
In this blog post, we have walked through the basics of ETL pipelines in Python, providing code examples and explanations at each step. The pipeline we created is a simple representation of how you can extract, transform, and load data, and similar processes can be applied to more complex data sources and transformations.
Key Points:
- ETL is pivotal in the data processing lifecycle, enabling organizations to transform raw data into actionable insights.
- Python is a versatile language that simplifies the creation of ETL pipelines through various libraries and frameworks.
- Data extraction, transformation, and loading can be efficiently handled with a well-structured approach.
This fundamental ETL workflow lays the groundwork for building more sophisticated data pipelines using Python.
Additional Resources
By following this guide, you can begin to implement your own ETL pipelines in Python, tailored to your organization's unique data processing needs
Search
Categories
- Coding (Programming & Scripting)
- Artificial Intelligence
- Data Structures and Algorithms
- Computer Networks
- Database Management Systems
- Operating Systems
- Software Engineering
- Cybersecurity
- Human-Computer Interaction
- Python Libraries
- Machine learning
- Data Analytics
- Systems Programming
- Cybersecurity & Reverse Engineering
- Automotive Systems
- Embedded Systems and IoT
- Compiler Designs and Principals
- Apps and Softwares
Recent Articles
- Uninformed Search Algorithms in AI
- Pandas Data Wrangling Cheat Sheet
- Complete Guide to Seaborn Data Visualization: From Theory to Practice
- Informed Search Algorithms in Artificial Intelligence
- Derivation of the Softmax Function
- Gradient descent — mathematical explanation & full derivation
- Understanding Standard Deviation and Outliers with Bank Transaction Example
- ETL Pipelines in Python Explained with Code and Examples